참조 : https://python.langchain.com/docs/modules/data_connection/vectorstores/
Vector stores | 🦜️🔗 Langchain
Head to Integrations for documentation on built-in integrations with 3rd-party vector stores.
python.langchain.com
Vector stores

Embedding 된 vector 값을 저장하는 DB
여기서는 Chroma 기준으로 테스트 진행함
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('sample/Test.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
db = Chroma.from_documents(documents, OpenAIEmbeddings())
query = "How to check DB Instance?"
# Similarity search
docs = db.similarity_search(query)
print('Output>', docs[0].page_content)
# Similarity search by vector
embedding_vector = OpenAIEmbeddings().embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector)
print('Output>', docs[0].page_content)- 첫번째 결과 - similarity search = 쿼리를 그대로 인자로 전달하여 쿼리 수행
- 두번째 결과 - similarity search by vector = 쿼리를 벡터로 만들고 이 벡터를 인자로 전달하여 쿼리 수행
- 두개의 결과는 동일함
참고
Chroma DB에 저장할 때 OpenAIEmbeddings() 를 수행하게 되면 파일이 큰 경우에 다음과 같은 에러가 발생할 수 있음
openai.RateLimitError: Error code: 429 - {'error': {'message': 'Request too large for text-embedding-ada-002 in organization org-piLmrmmd5BJoMxkmLsZM2Ryr on tokens per min (TPM): Limit 1000000, Requested 1006214. The input or output tokens must be reduced in order to run successfully. Visit https://platform.openai.com/account/rate-limits to learn more.', 'type': 'tokens', 'param': None, 'code': 'rate_limit_exceeded'}}
이는 OpenAI에 다음과 같은 제한때문에 발생함
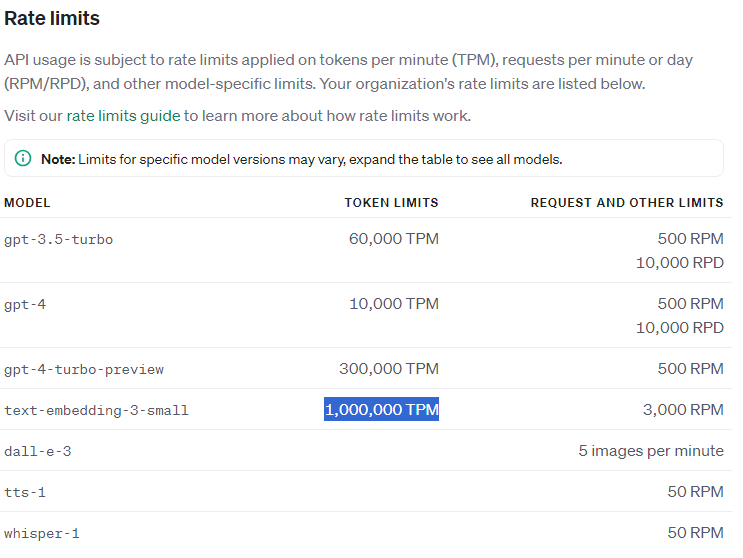
-> 이를 위해서는 초기 파일을 좀더 나눠서 embedding 시커야 함
Vector store 저장 후 사용하기
from datetime import datetime
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
DB_PATH_OPENAI = "./ChromadbOpenAI"
DB_PATH_STF = "./ChromadbStf"
mini_embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# Load the document, split it into chunks, embed each chunk and load it into the vector store.
raw_documents = TextLoader('sample/Test.txt').load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
chroma_openai = Chroma.from_documents(documents, OpenAIEmbeddings(), persist_directory = DB_PATH_OPENAI)
chroma_stf = Chroma.from_documents(documents, mini_embeddings , persist_directory = DB_PATH_STF )- 2개의 persistent 타입의 vector store 생성
- embedding model에 따라 openai의 embedding 알고리즘, stf 알고리즘으로 chroma db 생성
- 알고리즘에 따라서 embedding 되는 차원이 다름 > Vector가 생성되는데 몇 차원의 vector인지 차이가 남
- 차원에 따라서 DB size도 달라짐 (openai의 embedding 알고리즘의 Vector가 큼 - 1536 차원)
- Chromadb는 sqlite3를 기본으로 함
- 다음 프로그램에서 해당 DB를 사용 가능
from datetime import datetime
from langchain_community.document_loaders import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings.sentence_transformer import (
SentenceTransformerEmbeddings,
)
DB_PATH_OPENAI = "./ChromadbOpenAI"
DB_PATH_MINI = "./ChromadbMini"
mini_embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
chroma_openai = Chroma(persist_directory=DB_PATH_OPENAI, embedding_function = OpenAIEmbeddings())
chroma_mini = Chroma(persist_directory=DB_PATH_MINI , embedding_function = mini_embeddings )
query = "How to check AP Server?"
print("Query = ", query)
# Similarity search
docs_openai = chroma_openai.similarity_search(query)
print("")
print('Output using OPENAI . 1st >', docs_openai[0].page_content[:500])
print('Output using OPENAI . 2nd >', docs_openai[1].page_content[:500])
print('Output using OPENAI . 3rd >', docs_openai[2].page_content[:500])
docs_mini = chroma_mini .similarity_search(query)
print("")
print('Output using STF . 1st >', docs_mini [0].page_content[:500])
print('Output using STF . 2nd >', docs_mini [1].page_content[:500])
print('Output using STF . 3rd >', docs_mini [2].page_content[:500])- DB_PATH를 이용하여 기존에 저장된 Chromadb를 찾아서 사용 가능
- embedding_function을 어떤 것을 사용했는지 지정 필요 (어떤 알고리즘으로 저장 되었는지)
- 쿼리를 통한 similarity_search 수행하여 3개까지의 답변을 최초 500자 기준으로 표시함
'ML&DL and LLM' 카테고리의 다른 글
| (Docker) ollama + chroma로 RAG 구성 (0) | 2024.08.14 |
|---|---|
| LangChain - 2.6 Retrievers (0) | 2024.04.03 |
| LangChain - 2.3 Text Splitter (0) | 2024.04.02 |
| LangChain - 2.2 Document loaders (0) | 2024.04.01 |
| LangChain - 2.1 Retrieval concept (1) | 2024.03.29 |