Overview
- HANA Supports
- Disaster recovery support
- Backups : Periodic saving of database copyes in safe pace
- Storage replication : Continuous replication (mirroring) between primary storage and backup storage over a network (may be synchronous)
- System replication : Continuous update of secondary system by primary system, including in-memory table loading
- Fault Recovery support
- Service auto-restart : Automatic restart of stopped services on host (watchdog)
- Host auto-failover :Automatic failover from crashed host to standby host in the same system
- Data pre-load option 유용하게 사용 가능
- System replication : Continuous update of secondary system by primary system, including in-memory table loading and read-only access on the secondary
- Secondary server를 non-production system으로 사용 가능
- System replication은 양쪽(DR, Fault Recovery) 에서 모두 사용 가능
- Disaster recovery support
Backup
- Storage에 2가지 type의 데이터를 유지함
- Transaction redo log
- Data 변경 시 전체 data 말고 redo log 만으로 transaction durable 가능
- Outage 상황에서 대부분의 최근 consistent state는 log의 내용을 replay 하는 것으로 restore 가능
- Data changes (Savepoint)
- Page 단위로 모든 변경이 Disk에 write 됨 -> Restart 시간을 단축하기 위함
- Default 5분 단위
- 일반적으로 Older savepoint 들을 overwrite 하게 됨
- 특정 목적으로 freeze 가능 -> Snapshot
- Snapshot can be replicated in the form of full data backups (PIT recovery에서 사용 가능)
- Data corruption 등에 유용할 수 있음
- 특정 목적으로 freeze 가능 -> Snapshot
- Transaction redo log
- Databackup에 더하여 주기적인 log backup이 작은 데이터의 심각한 fatal storage fault로부터 복구를 가능하게 함
- Savepoint는 local storage, 추가적인 backup은 backup storage에 저장 가능
Storage Replication
- Hardware partner에 의해서 지원은 가능
- Continuout replication of all persisted data (Storage level replication certified by SAP)
- Complete된 transaction만 전달 됨
System Replication
- Primary system의 extra copy로 secondary system setup (Log shipping)

- Secondary system은
- primary system 옆에 위치 가능 = Planned downtime, storage corruption, local faults에 대응
- Remote site에 위치 = DR 시나리오
- Multitier system replication 가능
- Secondary 시스템의 모드
- Recovery mode
- All secondary system services constantly communicate with their counterparts, replicate and persist data and logs, and load data to memory
- Secondary에서는 request/query 처리 하지 않음
- 각 service component는 각 counterpart와 connection 생성, primary에 snapshot 생성을 요청
- Primary의 모든 log들이 persisted될 때 secondary system에도 역시 보내짐
- Transaction은 log가 replication 되지 않으면 commit 되지 않음
- Secondary system에 connection이 끊어지거나 secondary system이 crash되면 primary system은 간단히 구성 가능한 시간 초과 후 replication이 계속됨
- Secondary system은 유지되지만 수신된 로그를 즉시 재생하지 않음
- 로그의 리스트가 커지는 것을 막기 위해 incre
- mental data snapshot이 Primary system에서 secondary로 비동기적으로 전송됨
- Secondary system에 Takeover되기 위해 가장 최근의 Snapshot 이후의 log만 replay 필요함
- Snapshot에 추가해서 어떤 table column이 최근에 메모리에 load되었는지 등의 status information을 전송 함
- Secondary system은 해당 열을 pre-load 함
- 전체 시스템의 failover 발생 시 administrator는 secondary로 switch할 것을 지시
- Promary와 동일한 컬럼이 이미 pre-load된 Secondary system이 마지막 transaction을 replay 하며 primary가 됨 (Query를 받아 들이게 됨)
- Recovery mode
Service Auto-Restart
- One service에 대한 fault recovery
- HANA services(Index Server, Name Server 등) 중 하나를 disable시키거나 sw failure 등이 발생한 경우
- services는 service auto-restart watchdog function에 의해 재시작됨
- Restart 시 service는 데이터를 메모리에 올리고 수행을 계속 함
- 모든 데이터가 안전하게 유지되는 동안 recovery는 약간의 시간이 소요됨
Host Auto-Failover
- Failed host에 대한 fault recovery
- Local fault recovery의 솔루션
- System replication의 추가적인 / 대체적인 방법으로 사용 가능
- 하나 이상의 standby host가 추가됨
- Standby mode로 수행됨
- 어떤 Data도 가지지 않으며 어떤 request/query도 받지 않음
- 다른 용도로는 사용하지 못함 (Quality or test system)
- Active (worker) host에 문제가 생기면 stanby host가 자동으로 대신함
- Name server process (hdbnameserver) 또는 hdndaemon이 network request에 응답을 하지 못하는 경우
- instance가 stopped되거나 os가 shutdown / power off 되는 경우
- Host는 inactive로 mark되고 auto-failover가 trigger 됨
- Standby host는 모든 database volume에 access share 가능해야 함
- 공유된 (Network으로 연결된 storage server)에 의해 구현 -> 분산 file system

- 복구되면 failed host는 새로운 Standby로 rejoin 가능
- Name server process (hdbnameserver) 또는 hdndaemon이 network request에 응답을 하지 못하는 경우
- Host auto-failover 지원을 위해
- Database client는 Multiple host (Standby 포함)에 대한 설정 필요
- Failover시에도 적절한 connection 가능하도록 설정 필요
- 참고] Scale-out 시스템에서는 failing master host로부터의 failover는 standby가 설정되지 않아도 자동으로 trigger되며 worker host가 이전 master의 volume에 attach
HANA DB system replication
Overview
- provides the possibility to copy and continuously synchronize a SAP HANA database to a seconday location in the same or another data center
- High availability와 Disater recovery에 사용됨

- Replication Status
- unknown : Cannot connect to secondary
- initializing : Connect to secondary
- Syncing : Synchronize from primary
- Active : Service in sync with primary
- Error : Connection get glosed with error
- Verify System replication
- OS level
- <sidadm user> python $DIR_INSTANCE/exe/python_support/systemReplicationStatus.py
- HANA cockpit
- System replication
- OS level
Configuring SAP HANA System Replication
- System replication의 설정 및 관리는 다음에서 가능
- hdbnsutil을 이용한 command line
- SAP HANA cockpit
- SAP HANA studi
- SAP LaMa (Landscape Management)
- General prerequisites for configuration SAP HANA system replication
...더보기
-
General Prerequisites for Configuring SAP HANA System Replication
-
Primary & Secondary system 모두 설치/설정 되어야 함
- 양쪽 모두 독립적으로 up and running 되어야함
- Primary & Secondary system의 설정은 동일해야 함
- Host role의 이름, failover group 과 worker group은 identical 해야 함
- All configuration steps have to be executed on the master name server node only
- System replication landscape의 upgrade 도중에 현재 secondary system의 SW 버전은 primary system과 동일하거나 더 최신이어야 함
- Secondary system은 Primary와 동일한 SAP system ID <SID>와 instance number를 가져야 함
- 동일한 Host의 다른 system간의 replication은 불가
- .ini configuration은 양쪽 시스템이 비슷해야 함
- 모든 변경은 manually 생성되거나 SQL command로 다른 시스템으로 복제됨
- Host name은 달라야 함
- Log_mode는 'normal'로 설정 (global.ini [persistence] -> logmode = normal)
- normal = log segment가 backup 됨
- Primary system의 Data backup 또는 storage snapshot 수행 해야 함
- Log backup의 생성을 시작하는 것이 필요
- Activate log backup = Log shipping의 common sync point를 갖기 위한 필요사항 임
- 양쪽 시스템은 동일 endianness platform에서 수행되어야 함
- Multitarget system replication에서는 dynamic tiering은 지원되지 않음
-
- Overview of steps
...더보기
- Overview of steps
- Set up system replication on primary and secondary systems:
- Start the primary system.
- Create an initial data backup or storage snapshot on the primary system. In multiple-container systems, the system database and all tenant databases must be backed up.
- Enable system replication on the primary system (sr_enable).
- Prepare the secondary system for authentication by copying the system PKI SSFS .key and the .dat file from the primary system to the secondary system.
- For more information, see SAP Note 2369981.
- To set up system replication with XSA, copy the secure store files from your primary system to the same location on the secondary system before starting the secondary system.
- For more information, see General Prerequisites for Configuring System Replication.
- Register the secondary system with the primary system (sr_register).
- Start the secondary system.
- During failover, the secondary system takes over from primary system:
- Secondary system in data center B takes over from primary in data center A (sr_takeover).
- Stop primary system in data center
- When the primary system is available again, register it with the secondary system (sr_register). The roles are switched, the original primary is registered as a secondary system. The original secondary is the production system.
- Start the system in data center A.
- Failback to the original primary system:
- Send a takeover command from the system in data center A (sr_takeover).
- Stop the system in data center B.
- Register the system in data center B as secondary again (sr_register).
- Start the system in data center B.
- Disable system replication:
- Unregister the secondary system.
- Disable system replication on the primary system.
- Set up system replication on primary and secondary systems:
Replication Mode
- SYNCMEM (Synchronous in-memory)
- Primary system waits until secondary system has received in memory
- Data가 Secondary의 memory에 도달하면 바로 Acknowledgement back을 보냄
- Secondary의 Disk I/O의 속도는 Primary의 성능에 영향을 주지 않음
- Secondary와의 connection이 끊어지면 Primary는 Transaction처리를 local disk에만 쓰는 것으로 계속하게 됨
- Data loss 발생 가능
- Secondary가 연결되어 있는데 Primary / Secondary가 모두 Fail 되는 경우
- Secondary가 연결되어 있지 않은데 Takeover가 수행된 경우
- Primary system waits until secondary system has received in memory

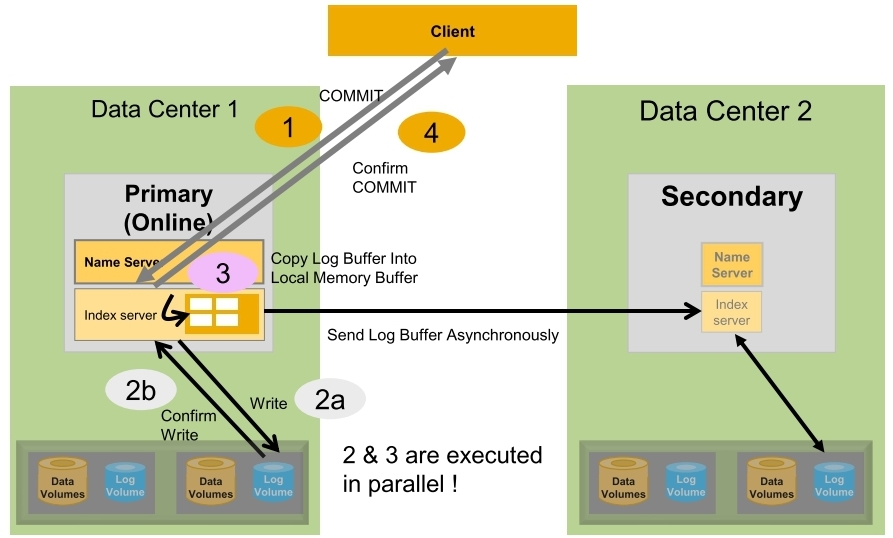
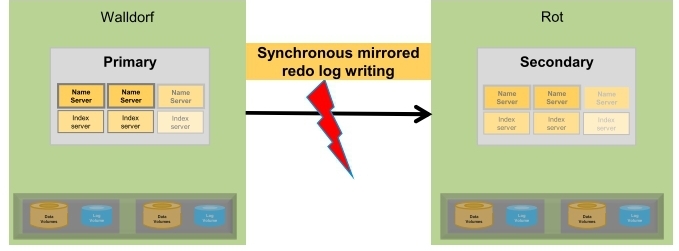
- SYNC (Synchronous)
- Primary system waits until secondary system has received data and persisted it to disk
- Data가 Secondary의 Memory에 도달하고 Disk의 log volume에 저장되면 Primary로 Achnoledgement back을 보냄
- Secondary와의 connection이 끊어지면 Primary는 Transaction처리를 local disk에만 쓰는 것으로 계속하게 됨
- NO Data loss
- Secondary가 연결되어 있는 한
- Secondary가 연결되어 있지 않은데 Takeover가 수행되면 loss는 발생가능
- Full sync option으로 수행 가능
- Log write is succssfull
= Primary & Secondary의 log buffer 내용이 log file로 쓰여 지는 것 - Secondary가 연결되어 있지 않은경우 Primary system은 transaction 처리를 suspend 시킴
- Data loss는 절대 발생하지 않음
- 설정 파라미터
- [system_replication] / enable_ful_sync
- Log write is succssfull
- Primary system waits until secondary system has received data and persisted it to disk

- ASYNC (Asynchronous)
- Primary system doesn't have to wait for secondary system
- Primary의 log buffer에서 secondary로 async하게 보냄
- Primary의 transaction처리는 primary의 log file에 써지고 secondary로 network을 통해서 전달하게 되면 commit 처리 됨
- secondary의 ack를 기다리지 않음
- Secondary의 IO를 기다리지 않아도 됨 -> 더 나은 성능을 보장
- 모든 서비스에 대한 secondary의 database consistency는 보장하나 takeover 시 data loss 발생 가능
- Primary system doesn't have to wait for secondary system
- Replication mode 변경
- hdbnsutil -sr_changemode --mode=sync|syncmem|async
- Replication mode 정리
| mode | memory log buffer in sync | log segments on disk in sync | primary suspends operation on secondary disconnect | secondary is prone to data loss on takeover |
| asynchronous | X | X | X | O |
| synchronous in memory | O | X | X | O |
| synchronous | O | O | X | X |
| synchronous + full sync | O |
Operation Mode
- Delta_datashipping
- Continuous log shipping에 추가해서 Default로 매 10분마다 Delta data shipping이 발생함
- 전달된 redo log는 secondary에서 replay 되지 않음
- Takeover 도중에 Redo log는 최종 전달된 Delta data shipment까지 replay 필요
- Continuous log shipping에 추가해서 Default로 매 10분마다 Delta data shipping이 발생함
- Logreplay
- 최대 하나의 전체 data shipping으로 초기 설정 이후에 redo log shipping이 수행됨
- Redo log는 도착 즉시 secondary에서 replay 되어 takeover 중에 이 단계가 불필요
- Delta data shipping이 필요하지 않음
- Secondary로 전송해야 할 데이터 양이 줄어듬
- SPS10 이하는 미지원
- if secondary로의 connection을 사용할 수 없다면
- primary는 다시 connection이 만들어진 후에 delta log shiping을 위해서
- log 영역에 redo log segment의 writing을 계속 하여 준비하게 됨
- 이 log segment들은 secondary가 다시 동기화될 때까지 RetainedFree 로 mark됨
- 이 경우 log volume이 가득차게되면 Risk -> 이를 방지하기 위해
- Secondary를 더이상 사용하지 않으면 unregistered 필요 (sr_unregister)
- Secondary로 takeover가 끝나면 이전의 primary는 disabled 되어야 함 (sr_disable)
- 이 경우 log volume이 가득차게되면 Risk -> 이를 방지하기 위해
- logreplay operation은 history table을 지원하지 않음
- Logreplay_readaccess
- Active/Active (read enabled) secondary system이 가능
- Logreplay operation mode와 다음이 비슷
- Continuous log shipping
- secondary의 redo log replay
- 필요한 초기 전체 data shipping and takeover 관련
- HANA 2.0 SPS01 이상 가능
- Operation mode 변경
- mode 변경을 위해서는 sencondary는 offline 이어야 함
- logreplay 또는 logreplay_readaccess 모드로 switching 시 full data shipping이 필요하지 않음
- 단 logreplay에서 delta_datashipping으로 돌아갈 때는 필요함
- 관련 Command
hdbnsutil -sr_register
--name=<secondary_alias>
--remoteHost=<primary_host>
--remoteInstance=<primary_systemnr>
--replicationMode=[sync|syncmem|async]
--operationMode=[delta_datashipping|logreplay|logreplay_readaccess]
HSR Operation
- Restart
- Restart of primary
- Secondary reconnects automatically if it was connected before stopped
- Restart of secondary
- Secondary reconnects automatically if primary is online
- Primary sends incremental data
- Primary sends the missing redo log
- Restart of primary

- Log shipping Timeout & Reconnect Time interval synchronous replication
- Primary
- Stops log shipping when waiting longer than logshipping_timeout for acknowledge after sending buffer to secondary (default 30 sec)
- Secondary
- Tries to reconnect in interval defined by reconnect_time_interval (defualt 30 sec)
- Primary는 reconnect 후 incremental data을 전송함
- Primary
Takeover
- Primary system이 재해나 planned downtime으로 사용가능하지 않고 secondary로의 전환이 결정된 경우 Seconday system에서 takeover를 수행할 수 있음
- Steps and nameserver trace
- Start takeover
- issuing a normal takeover
- Open data persistence based on last savepoint
- Prepare takeover started
- point in Time Restart: restartLogPos=0x00000000
- Recovery finished
- Load Row Store
- RS: metadata
- Rebuilding system indexes done
- Assign volumes
- assin volume 2 to selbld104:33707
- re-assign for databaseld 3 volume 2 returned successfully
- Finish takeover
- finished successfully ~~ SRTAKEOVER
- Start takeover

Check configuration & statistics
- hdbcons -e hdbindexsrver "replication info"
Data transferred to the seconary system
- Mode의 선택에 따라 DB는 secondary로 다른 type의 data set를 전달하게 됨
- Initial full data shipping
- System replication이 설정되면 primary의 disk에 HANA 내부 위치 Snapshot으로 생성된 전체 data set이 처음으로 보내짐
- Delta data shipping
- 마지막 Full 또는 delta data shipping 이후에 변경된 데이터는 때때로 primary의 data 영역에서 secondary의 data 영역으로 전송됨
- Default는 매 10분
- logreplay 와 logreplay_readaccess를 사용하는 경우에는 필요하지 않음
- Continuous redo log shipping
- Primary의 모든 committing write transaction은 redo log buffers를 생성하고 secondary로 계속 보내짐
- 참고
- global.ini [system replication] -> datashipping_parallel_channels (default 4) = full and delta data shipping 시 parallel network channel을 사용하게 됨
- Initial full data shipping
- Setup SAP HANA system replication
...더보기
Setup SAP HANA system replication
- from the primry system
- Procedure
- On the Overview page of the primary system, choose the System Replication tile. Initially this tile displays the message System replication is not yet enabled for this system.
- The System Replication page opens.
- If you performed a data backup before enabling system replication, this page displays overview information on the primary system on the top left and the Configure System Replication link on the top right.
- Choose Configure System Replication.
- The System Replication Configuration dialog opens, allowing you to run the configuration in background.
- Enter the logical name used to represent the primary system in the Tier 1 System Details screen area.
- Enter the logical name used to represent the secondary system in the Tier 2 System Details screen area.
- Select the secondary system host and mark the checkbox below this area to stop the system.
- Select a replication mode. For more information on the available replication modes, see Replication Modes for SAP HANA System Replication.
- Select an operation mode. For more information on the available operation modes, see Operation Modes for SAP HANA System Replication.
- Decide whether to initiate data shipping or not.
- Check Start Secondary after Registration.
- Optional: To add a new system to your system replication landscape configuration click Add Tier 3 System on the bottom left.
- Choose Configure System Replication. The System Replication Configuration dialog opens, allowing you to run the configuration in background.
- On the Overview page of the primary system, choose the System Replication tile. Initially this tile displays the message System replication is not yet enabled for this system.
- Procedure
- from the primary and the secondary system
- Procedure
- Admin guide 참조
- Procedure
Full Sync Options
- Secondary로 log shipping이 수행되지 않으면 primary는 block됨
- M_SERVICE_REPLICATION.FULL_SYNC 컬럼
- DISABLED : Full sync is not configured
- ENABLED : Full sysnc is configured
- ACTIVE : Full sync mode is configured and active
- Secondary가 stop되면 FULL_SYNC를 disable 하지 않으면 primary는 block됨
- Multitarget system replication에서
- global.ini [system_replication] -> enable_full_sync[<secondary_site_name>] = true
Data and Log Compression
- Log
- Log buffer tail compression
- 모든 log buffer는 filler entry에 의해 4kb 경계에 정렬됨
- Network를 통해 전송되기 전 buffer에서 filler entry를 잘라내고 buffer가 secondary에 도달하면 다시 추가됨
- 따라서 only the net buffer size만 secondary로 전달됨
- filler entry의 size는 4kb 이하이며 전송된 log buffer당 최대 크기 감소
- log buffer의 크기가 상당히 크면 압축 비율이 제한됨
- log buffer tail compression은 기본적으로 설정됨
- Log buffer content compression
- Parameter
- global.ini [system_replication] -> enable_log_compression = true
- Parameter
- Log buffer tail compression
- Data
- Data page compression
- Parameter
- global.ini [system_replication] -> enable_data_compression = true
- Parameter
- Data page compression
- log buffer and page content compression
- Long distance에서 사용될 때 유용함
- lossless compression algorithm (lz4) / default는 turned off
- 속도와 압축비율때문에 선택됨
'Database' 카테고리의 다른 글
| [HANA] MVCC and GC (0) | 2019.04.14 |
|---|---|
| [HANA] HANA Backup & recovery (0) | 2019.04.14 |
| [HANA] SAP Notes 2600030 - Parameter Recommendations in SAP HANA Environments (0) | 2019.04.12 |
| [HANA] Memory Control (0) | 2019.04.11 |
| [HANA] Timeout관련 파라미터 (0) | 2019.04.11 |
