Architecture of the SAP HANA

Architecture of the SAP HANA indexserver

- External Interface
- SQL, MDX(Multidimensional Expressions), Web interface가 접속이 가능하도록 함
- Request Processing and Execution Control
- Interface와 명령에 따라 처리를 위한 다른 구성요소를 사용할 수 있음
(SQL script 구현은 Calcuation Engine에서 실행됨)
- Interface와 명령에 따라 처리를 위한 다른 구성요소를 사용할 수 있음
- Relational Engine
- HANA의 table data는 2개의 다른 relational store (Row store and column store)에 저장됨
- 데이터의 storage mechanism을 결정함
- Storage Engine and Disk Stroage
- 일관성을 유지하고 내구성 변화를 유지하기 위해 Page Management 및 Logger가 사용되는 Storage engin이 사용됨
- Restart 시 가장 최신의 committed state로 북구되도록 함
- Transaction은 전체적으로 수행되거나 전체적으로 undone 됨
- Disk Storage는 Data volume과 Log Volume으로 나뉘어짐
- 변경은 transaction의 commit 전에 log area에 저장 되어야 함 (Synchronous writing)
- Data area는 전체 main memory 내용을 특정한 시점에 저장 함 (Asynchronous writing)
- Connection and Session Management
- Authenticates a client to generage session
- 세션별 파라메터 등을 관리
- auto-commit, current transaction, isolation level 등
- Authorization management
- Invoked by HANA to check whether the user has required priviledges for requested resource
- 특정 operation이나 특정 object의 권한을 유저에게 부여
- Planning Engine
- Transformation 동안 Data planning을 결정
- Determining different aggregation levels
- SQL Processor
- Calculation Engine 전에서 Server와 Client의 최초이 communication line
- SQL Parser, SQL Optimizer, SQL Executor로 구성됨
- SQL처리를 담당하며 연산(Calculation)은 Calculation Engine으로 전달 됨
- 나머지는 적당한 engine이나 operator에게 전달 됨
(Transaction rollback, data definition, MDX query 등은 모두 SQL Processor 외부 operator들로 분리됨)
- 나머지는 적당한 engine이나 operator에게 전달 됨
- Calcuation Engine
- HANA request execution의 프로세스 단계 중 두 번째에 해당하며 SQL Processor에 의해서 연산이 전달됨
- HANA Data Model (또는 Calculation View)는 Calculation Engine을 직접 사용하므로 HANA의 핵심 요소임
- In-memory columnar storage와 Cache 최적화와 같이 Calculation mode의 활용은 다음과 같은 방법으로 도움이 됨
- 데이터 모델의 실행에서 고성능 (실시간 aggregation / calculations)
- Predictive and geospatioal과 같은 application-specific operation의 수행
- Parameterized calculation model
(전통적인 SQL query의 사용 대신에 structure of the calculation in the model을 정의함)- Table, field, 특정 값들과 같은 source로 부터 직접 데이터를 가져옴
- 모델이 수행될 때 특정 Calculation이 수행되도록 지정 (i.e. IF Statement)
- Output에서 원하는데로 데이터를 Display함
- 이와 같은 방식으로 구조화된 모델을 사용하게 되면 Calculation Model 실행이 최적화 되어서 보다 효율적인 처리를 위해서 결과집합을 줄일 수 있음
- Filter 적용, projection을 통해 field 선택, aggregation와 join이 하나의 노드로 합쳐지며 multiple CPU Core에 걸쳐서 병렬 처리여부를 결정하게 됨
- 이러한 Calculation model이나 calculation view는 analytics application에 직접 연결을 위해서 사용 가능
- 요약하면
- Create logical plan for calculation duing query execution
- Domain specific model로부터 calculation model을 생성
- Data의 정확도를 책임짐
- Application Engines
- Application-specific 로직을 포함한 request는 관련된 built-in operator를 수행함
- 해당 built-in application operator는 HANA가 다른 Data type (text, spatial, graph, predictive, C++) 들을 dramatic하게 처리하도록 함
- 예를 들면 R operation, graph spatial data 처리에서 해당 operator를 가지고 있음
SQL Processor 상세
- SQL Parser
- 우리가 제공한 SQL문이 최초로 지나감
- SQL문을 input으로 해서 SQL 문법에 따라서 Parsing 수행
- 문법적 적합성을 체크 (테이블이나 컬럼 이름이 정확한지 등)
- SQL Optimizer
- Parse Tree를 Relational algebra 로 변경함
- Relational algebra : Selection, join, aggegation과 같은 연산자를 포함
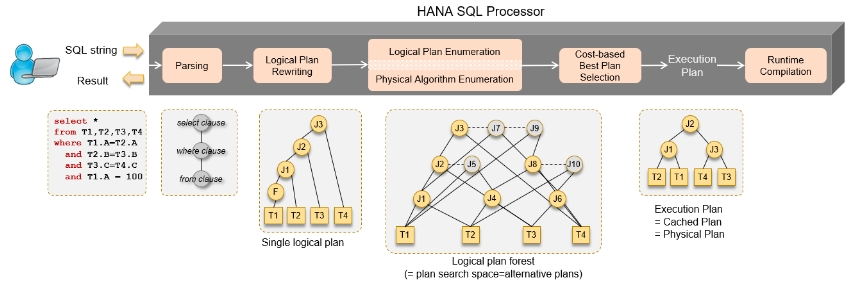
- Relational algebra : Selection, join, aggegation과 같은 연산자를 포함
- Plan creation 단계 동안 SQL string에 주어진 정보는 최선의 실행계획을 찾기 위해서 생성한 multiple plan에 사용됨
- Query rewrite 수행 됨
- 이상적으로 join reordering은 모든 join들 중에서 가능하며 역시 다른 operator들도 plan variants에서 이동 가능함 -> correct result를 보장 해야 함
- High-level perspective (removal of join, loop optimization by aggregating data before executing futher calcuation or joins)가 언제나 가능한 것은 아님
- 에) aggregation push-dwn
- SUM(ROUND(convert_currency(VALUE, ERU), 2 )) --> is not equivalent to
ROUND(convert_currency(SUM(VALUE),EUR),2)
- CDS view 관련 Recommendations
- CDS views는 될 수 있는 한 Simple하게 유지 해야 함
- 복잡도가 굉장히 높은 상황이라면 복잡하면 best plan을 선택하지 못할 수 있음
- complex SQL statement의 실행계획과 실행시간은 Plan 재생성 이후에 변경 될 수 있음
- Product에서 사용하기 전에 운영환경과 같은 데이터를 가지고 테스트를 수행 해야 함
- HANA upgrade 후 또는 많은 수의 데이터가 급격하게 변경된 경우에 business-critical SQL Statement의 수행은 관리 되어야 함
- 모든 SQL 성능은 HANA Plan Cache 또는 SQLM (SQL monitoring tool on ABAP server)로 모니터링 해야 함
- CDS views는 될 수 있는 한 Simple하게 유지 해야 함
- 짧은 시간 내에 많은 가능한 plan들 중에서 판단을 해야 하기 때문에 가능한 limit number of possible plan 있음
- 5개 이상의 join이 들어가게 되면 잘못 판단할 가능성이 있음
- 복잡한 SQL Statement인 경우 re-compilation of plan에서 동일한 plan이 선택될거라고 확신할 수 없음
- SQL processor는 끔찍한 데이터 모델을 수정하지 못하거나 (예를 들어 secondary index 추가 또는 critical field의 연산거부에 의한) 데이터의 access가 어려움 (Filter 없는 전체 데이터 읽기)
- 예를 들어 CDS view가 calculated key를 아래와 같이 가지고 있을 떄
define view cdsTest as select from dbtab { key CONCAT (fld2, fld3_ AS concatKey, ... } - WHERE절의 filter로 해당 field가 사용되는 경우, filter가 수행되기 전에 전체 데이터에 대한 calculation (여기서는 CONCAT()) 가 수행되어야 함
- Join 조건에서 Calculated filed가 사용되면 Join 된 분기 주에 하나의 Filter에 대한 Push-down을 방해할 수 있음
- 예를 들어 CDS view가 calculated key를 아래와 같이 가지고 있을 떄
- Plan 생성 시 검토하는 요소
- SQL Statement
- Data Statistics : Test 시스템과 Prod 시스템에서의 수행이 다를 수 있음
- Indices : Secondary index를 사용할 수 있음
- Physical schema design : 파티션 여부, 인덱스 보유 여부 등
- HANA upgrage 후에 일부 SQL statement는 plan이 변경될 수 있음
- Parse Tree를 Relational algebra 로 변경함
- SQLExecutor
- Client 요청을 관리하고 simple statement를 수행
- Column store뿐만 아니라 row store에 대한 OLTP-like statement 처리를 담당
- 관련 파라미터
- sql_executors (soft_limit) - 0 (unlimited) HANA node당 SQL executor 수
- max_sql_executor (hard_limit) - 0 (unlimited) Hana node당 최대 SQL executor 수
- JobExecutor
- Job dispatching subsystem
- 대부분의 모든 남아있는 병렬 Task들이 JobExecutor에게 dispatch되고 JobWorker thread에 할당 됨
- Parallel 프로세싱 처리
- OLAP 부하에 추가해서 table upadate, backup, memory garbage collection과 savepoint write와 같은 operation을 수행함
- 관련 파라미터
- max_concurrency - 0 (unlimited) HANA node별 jobWorker에 의해 사용되는 논리적 CPU의 최대 개수
- max_concurrency_hint - 0 (unlimited) 개별 병렬 처리르 위한 Job의 수
Statement Execution and Resource handling

- JobExecutor에 의한 Parallel statment 수행

Indexserver Procedure

SQL PLAN 관련 메모리

- SQL 처리 단계
- 전체 처리 시간에서 상당한 부분을 차지함
- 준비된 Statement가 재사용 되지 않을 때 문제가 발생 (Bind 변수가 사용되지 않은 경우)
- 문제를 해결하기 위해서 Plan Cache 사용
- HANA Plan Cache
- Store optimized SQL statement in a plan cachedSQL String + some additional info와 complied query excution plan을 포함 함
- Plan이 무효화 되거나 제거되지 않은 한은 다시 parsing되거나 recompile 되지 않음
- Plan cache entries는 관련 Data structure가 변경되면 무효화 됨
- Join Engine은 데이터 소스와 관련된 데이터가 많은 수가 변경된 경우 recompile 수행을 하도록 함
- M_SQL_PLAN_CACHE.LAST_INVALIDATION_REASON 에서 확인 가능
- Identical Statement
- 커멘트의 추가도 다른 SQL로 간주하여 다른 Plan을 가질 수 있음
- ABAP의 SQL에 대해 WHERE 절의 필드를 accessed dictionary object (table or SQL view)의 필드의 순서와 동일한 순서로 지정하는 것이 좋음
- SQL statement의 파라미터 (CDS view 파리미터와 WHERE절, GROUP BY, ORDER BY의 파라미터)
- Bind 변수 사용 해야 함
- 커멘트의 추가도 다른 SQL로 간주하여 다른 Plan을 가질 수 있음
- Recommendation
- CDS view 파라미터나 WHERE절의 파라미터를 사용하는 ABAP에서 수행된 SQL Statement의 수행은 Bind 변수 기반으로 수행되어야 함
- 안정적인 runtime result와 재생성가능한 Plan을 위해서 Bind변수나 Literal에 대한 사용을 검토해야 함
- SQL Statement의 작은 변경도 Plan 변경을 만들 수 있음
- ABAP에서 SQL statement는 'cache-friendly'로 구현할 것
- 예) WHERE절의 필드를 accessed dictionary object의 필드 순서와 동일하게 만들 것
'Database' 카테고리의 다른 글
| [HANA] In-Memory Computing 기본-1 (1) | 2019.04.21 |
|---|---|
| [HANA] Calculation View (0) | 2019.04.20 |
| [HANA] SQL Statement Collector (0) | 2019.04.18 |
| [HANA] Cache Memory (0) | 2019.04.18 |
| [HANA] HANA2.0 SPS04 - 요약비교 (0) | 2019.04.18 |
